这里介绍分类数据绘制散点图的常用命令stripplot。
一般的散点图得XY,但是对于分类数据,X通常不是数值,而是一些标签,比如样品名称。这个时候如果还想绘制散点图方便查看数据的分布情况(主要是比简单的柱状图更能呈现采集数据量大的效果),推荐使用 sns.stripplot 命令。举例如下:
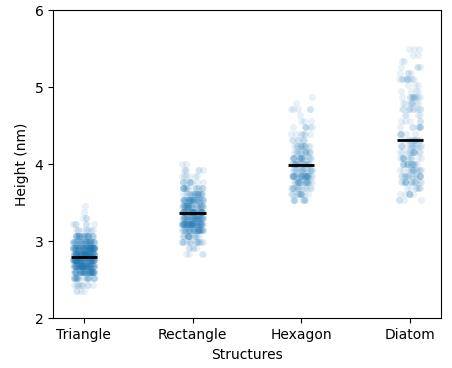
如上图所示,每种样品的数据因为比较多,所以增加了透明度(alpha)。同时为了避免重叠,还增加了抖动(jitter)。最后为了方便查看均值,还额外绘制了代表均值位置的短横线。
具体作图代码如下:
plt.figure(figsize=(5,4))sns.stripplot(data, x='Sample', y='H', alpha=0.1, jitter=True)
# 计算每个 'Sample' 的平均值,也可以考虑使用中位数average_heights = data.groupby('Sample')['H'].mean()# 获取 'Sample' 列的唯一值,这决定了 x 轴上的类别顺序samples = data['Sample'].unique()# 定义横线的水平偏移量,这个值决定了横线的宽度# 你可以调整这个值,直到横线的宽度在视觉上与 stripplot 中的点分布宽度相匹配offset = 0.12 # 这是一个经验值,可以根据需要调整
# 遍历每个样本及其平均值,并在图表上绘制短横线for i, sample_name in enumerate(samples): avg_height = average_heights.loc[sample_name] # 计算横线的起始和结束 x 坐标 # stripplot 会将每个类别放在整数位置 (0, 1, 2...) x_start = i - offset x_end = i + offset # 绘制黑色短横线,通过zorder设置让横线置顶 plt.hlines(avg_height, x_start, x_end, color='black', linewidth=2, zorder=3)
plt.xlabel("Structures")plt.ylabel("Height (nm)")plt.ylim(2, 6)plt.yticks([2,3,4,5,6])plt.savefig(os.path.join(wks, '250707_height_plot.png'), dpi=300)