对于曲线拟合,如果数据点太少,可能导致拟合效果糟糕。所以有时候需要一维插值。
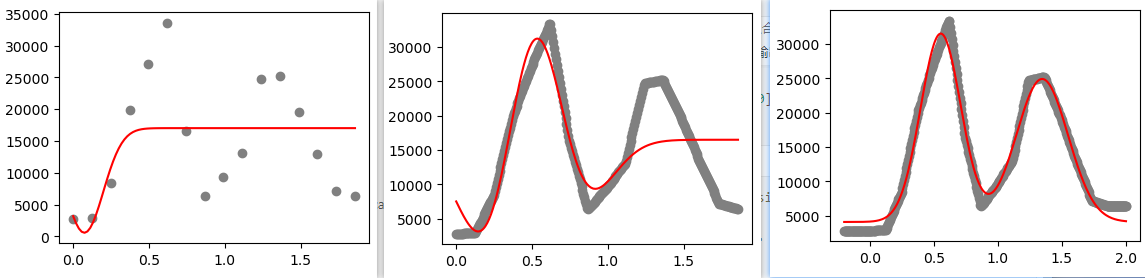
我就遇到过这种情况,如上图所示,原始数据中采样数太少,然后还想做双峰拟合,结果啥也不是。线性插值之后,双峰拟合的效果好了一点,但还是不理想。因为这两个峰的两侧基线可能相差较大而且数据点比较少,所以我又增加了侧翼,这才拿到比较好的拟合效果。
单峰拟合与双峰拟合详见其它博客:
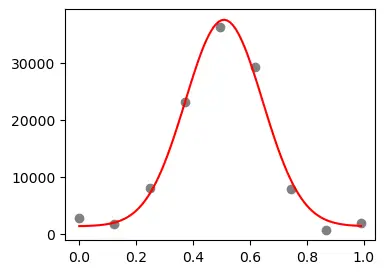
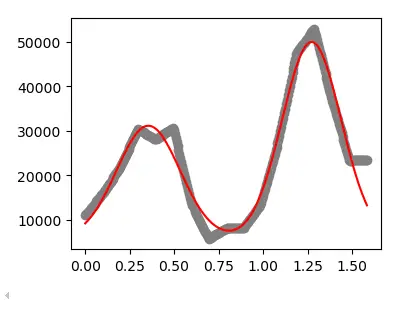
同样是image j line profile csv 读取的数据表作为输入,插值函数如下:
from scipy.interpolate import interp1dimport pandas as pd
def interp(c:pd.DataFrame, n=300): ''' c: 读取的imagej中划线测量的profile数据,包含distance和value两列 n: 插值后的数据点数量 ''' x = c.distance.values y = c.value.values f = interp1d(x, y) x2 = np.linspace(x.min(), x.max(), n) y2 = f(x2) return x2, y2然后增加两侧数据点,其实就是拉长水平线。但这个步骤慎重使用,纯粹是为了提高拟合效果拿到更准确的参数,所以这个函数复用性不大,仅作记录。
def add_flank(x2, y2, left_bound=-0.2, left_n=50, right_bound=2, right_n=50): # 注意这个 flanking 还不能增加太多,稍微多出来一点就行,不然也很影响 x4 = np.linspace(left_bound, x2.min(), left_n) x5 = np.linspace(x.max(), right_bound, right_n) xx = np.hstack((x4, x2, x5)) yy = np.hstack((np.ones((left_n,))*y2[0], y2, np.ones((right_n,))*y2[-1])) return xx, yy