
终于把面向初学者的 python 基础教程完成了。网上名为「python教程」的内容浩如烟海,但是大多都是面向软件开发人员的教程,其中代码知识极广极深,并不适合以成像数据分析为目的的小众科研用户。
为啥要学python编程
且慢,为啥要学 python 呢?图像数据分析,前面已经学习了「ImageJ基础教程」,甚至还有「ImageJ进阶教程」,难道还不够吗?我认为对于刚进入实验室头一两年的新生,ImageJ是足够而且必要的,但随着研究课题不断深入,以及要处理的数据量和数据分析复杂程度的不断增加时,ImageJ 可能就捉襟见肘了。
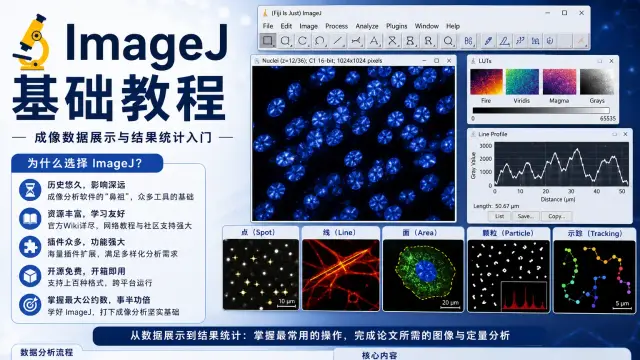
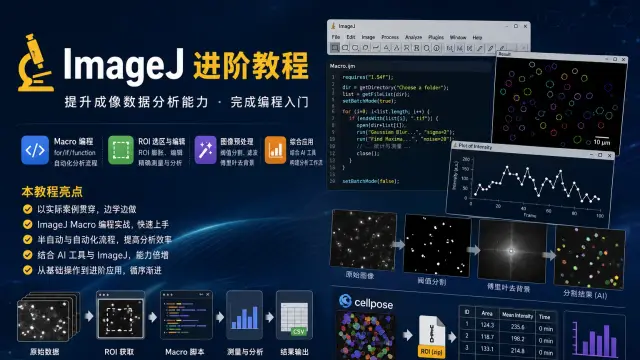
除了 ImageJ,还有大量其它软件可供选择。比如一些商业化的软件Amira, Imaris,Arivis,Aivia 等等,或者是开源的其它软件,比如 Ilastik,Icy 等等(image.sc论坛中还有更多),甚至以 python 代码为主的还有 napari 等,这么多工具和各种各样的插件,难道不够用还要自己学习编程吗?
首先,学习编程和使用上述软件并不是非此即彼的关系。如果因为自己会编程就什么问题都尝试自己编程毫无疑问是愚蠢的。事实上很多编程教程都会在开篇就告诫大家,「不要重复造轮子」。
然后上述各类软件工具通常满足的是已经被解决的比较大众化的需求,特别是商业软件,只有是比较普遍的需求它们才能够赚到钱。来自科研一线的数据分析需求总是各不相同且日新月异。实际经常出现的情况是:一个分析需求需要多种工具配合来满足其中 95%,剩下5%要靠自己手动操作。然后这5%就成了关键限速步骤。
事实上这5%的工作量也分两种情况。一类是真的难,需要独特的算法。但这一类概率很低,多查查资料问问大佬总归能找到解决方案,所以这里不作过多讨论。
第二类是重复繁琐的难,这一类非常常见。通常是需要自动化地做好大量数据在多个分析工具(甚至是功能模块函数)之间的流转,或者是一些简单的文件IO操作。第二类情况就属于是 python 编程可以大展身手的地方,毕竟它作为「胶水语言」的响亮名头不是盖的。
内容安排
搞定了「学习python的必要性」这个问题,接下来就要说下我这份「python基础教程」的主要内容。
秉承前面 ImageJ 教程系列的风格,这份 python基础教程以完整实例贯穿整个教程,将「数据结构」、「语法」、「常用模块」等等内容糅合到实战当中。我不会按部就班地给大家从什么「变量」、「列表」、「字典」这种编程的概念讲起。概括起来本教程主打实用,核心就是四个字:边干边学。
开干之前,需要先准备好 python 的编程环境,我推荐 Anaconda + VSCode,具体可以看看我之前的博文👇。
INPUT:本教程充分与前面的 ImageJ 教程衔接。展示了如何使用 python 读取 ImageJ 保存的文件来进行后续分析。在文件读取方面,主要以 TIFF 图像文件,CSV数据表文件和 选取ROI记录文件为例。具体可见下方博文。


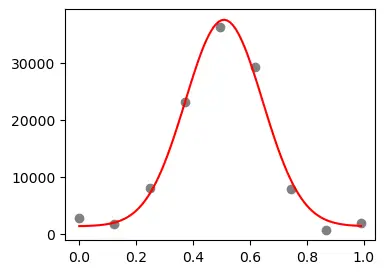
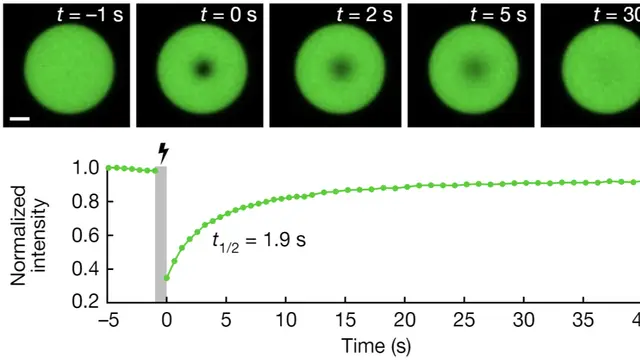
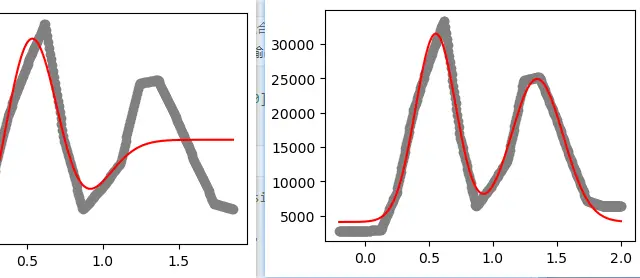
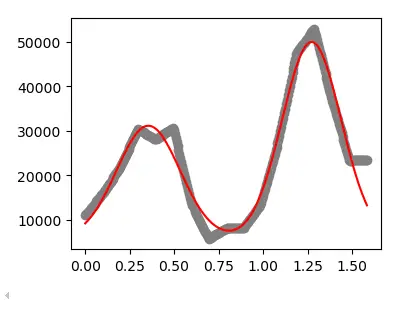
ESTIMATE:读取了这些数据文件要干什么呢?一个例子是展示了根据ImageJ划线测量的 profile 来估计成像分辨率。这里主要是涉及到了曲线拟合。曲线拟合能够帮助我们提取原始数据中隐含的重要模型参数。曲线拟合非常常用,除了估计分辨率,还能估计荧光漂白恢复时间。具体可见下方博文。
CALCULATE:除了曲线拟合,我们可能还需要对图像中的信息进行加减乘除等简单运算。例如提取ROI内的所有像素值然后直方统计。这里我提供了一个实例,展示了一种简单的信噪比估计方法。

OUTPUT:最后,当我们使用 python 完成了分析之后,还要把结果再整理和保存起来。图表图表,从图到表。所以我喜欢尽量保存数据结果为表格的形式。详见👇
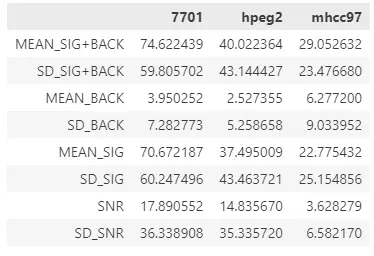
事实上在数据分析过程中保存一些好不容易得到的中间数据也是非常必要的。这一点我在中间部分的博文中也多有提及。
小结
因为这个教程是一个实例中拆解出来的,所以从 input 到 calculate,estimate 到最后 output,还是比较完整的。
在这个教程中,大量核心功能我都是使用的第三方的模块(俗称调包侠)。比如使用 pandas 来处理表格,通过 numpy 来处理图像数值矩阵,通过 AICSImage 和 roifile 来读取图像文件和ROI 记录,通过 curve_fit 来做曲线拟合…。这些模块也是软件工具的一种形式,只不过是以代码的形式存在。
学编程的好处就是自然而然地获得「函数」思想,所以这里可以更概括一点地说;一切工具皆函数,管好Input和Output,我们只需for和if。
最后附上本教程使用的数据集,方便大家练习。👇
链接: https://pan.baidu.com/s/1Q8WNpuTXN-KagisfsiSSJA
提取码: uruh