介绍pandas模块用于数据表分类汇总和导出。
承接上文,我们对每个数据的计算中间结果都存放到一个字典中,再把多个数据 item 放到一个列表 box 中。接下来就需要收集我们所有的计算结果,整合到一个数据表(dataframe),以便汇总分析。具体代码如下:
data = []for item in box: print(item['img_fp'], len(item['values'])) df = pd.DataFrame() df['intensity'] = item['values'] df['img_id'] = item['img_id'] df['group'] = item['group'] df['cell'] = item['cell'] data.append(df)data = pd.concat(data, ignore_index=True)
# 保存中间数据,以备不时之需with open('data3.pkl', 'wb') as f: pickle.dump(data, f)这里就是一个循环遍历,访问每个数据 item,从中提取出我们想要的信息,然后写入一个 dataframe。
需要注意的是,由于 item['values'] 是数值,而 group 还有 cell 这些都是字符串类型。而且长度还不一致。所以这里创建了一个空白 dataframe (变量名为 df)之后,首选填充 item['values'] ,这个 dataframe 的长度就和 values 一致,然后再赋值其它的非数值列,会自动补齐长度。但是这个 dataframe 中的 values 列已经发生了类型转化,从数值变为了文本,后面也是需要注意的。
每个数据 item 都会得到一个 dataframe,然后我们使用一个列表把它们收集起来,遍历结束后使用 pd.concat 方法将这些 dataframe 合并成一张数据表就行。

接下来我们要计算每种细胞的信噪比,就会变得很方便。如下所示:
gps = data.groupby('cell')pig = []for cell, df in gps: print(cell, '======') gp1 = df.groupby("group") a = gp1.get_group('u1') b = gp1.get_group('ctrl') res = calculateSNR(a, b) pig.append(res)这段代码中,先按dataframe 中 cell 列进行分组,然后对每种 cell 进行遍历,此时得到的是每个 cell 下所有的数据,然后进一步按 group分组,得到信号和背景的数据,进而计算信噪比,其结果使用列表收集起来(请忽视示例中随性的列表命名)。
但是这个pig 列表收到的到都是一个个的字典,还需要进一步整合成我们习惯看的表格。这个可以通过下方代码实现:
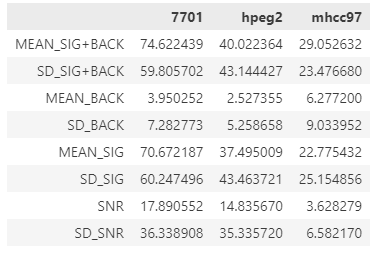
# 整理到一个summary的表格pig2 = [pd.Series(x) for x in pig]pig3 = pd.concat(pig2, axis=1)pig3.columns = ['7701', 'hpeg2', 'mhcc97']pig3.to_excel("SNR_summary.xlsx")这里首先使用 pd.Series 方法将字典转换下对象,原先的字典的 keys 会变为 pd.Series 的 index。再然后我们继续使用 pd.concat 方法把所有的 pd.Series 合并,注意 pd.concat 默认方向是纵向(axis=0, add row),这里的合并方向是横向(axis=1, add column)。合并之后,注意给 column 命名。这个汇总的结果可以保存为 excel 方便查看。
如果要对中间数据做一些直方图,可能要需要保存每个细胞不同条件下的数据表,则可以通过以下代码:
import pickleimport pandas as pd
with open('data3.pkl', 'rb') as f: data = pickle.load(f)
gps = data.groupby('cell')for cell, df in gps: gp1 = df.groupby("group") for group, df1 in gp1: gp2 = df1.groupby("img_id") for pid, df2 in gp2: df2.to_csv(f'{cell}_{group}_{pid}.csv', index=None)